New Tool Tuesday #2
Sherlock
Sherlock is an OSINT python tool developed by Siddharth Dushantha to discover user accounts across several hundred social networks. This tool is still being maintained by Siddharth and by 97 contributors. What makes this tool unique is the JSON database of websites connected to this tool. This database is the secret sauce that helps with tool efficiency and reliability. At the time of writing, the database contains 323 different websites for Sherlock to enumerate and figure out if the specified user account exists.
Tool Setup:
You can very quickly get this tool up and running! As long as you have python 3.6 installed just follow the installation instructions from Github.
Tool Execution:
At the very basic level, this tool can be executed by running the following command:
py sherlock.py username
- Sherlock will start enumerating websites and print the found websites to the screen
- You can view the full list of websites included in the scan within the sites.md file
- A results txt output file will also be made in the current working directory
To make this tool a little more efficient, i reccommend using the --timeout parameter to prevent waiting on those slow sites:
py sherlock.py username --timeout 30
Multiple Username execution:
If your OSINT target uses more than one username, you can specify multiple usernames to use on the same run:
py sherlock.py username1 username2 username3
Tunneling Network Traffic:
Sherlock offers two different methods to tunnel your network traffic to keep your attack machine anonymous.
You can tunnel your web requests through a proxy:
py sherlock.py username --proxy socks5://127.0.0.1:1080
Or you can tunnel your web requests through the Tor network:
py sherlock.py username --tor
Report Output Options:
By default, this tool outputs the results into a txt file with naming convention username.txt .
If you anticipate a large number of results, you can output your results into a CSV file:
py sherlock.py username --csv
- this option makes it easier to check off which websites you have reviewed
If you are executing this tool against multiple usernames, then you will want to use the folder output option to store all results into a separate directory:
py sherlock.py username1 username2 username3 --folderoutput ./targets
Efficiency Techniques:
What makes this tool so great is the speed of execution. Sherlock is able to enumerate 323 sites in under one minute (your speed may vary depending on your internet connection). This section is dedicated to exploring the techniques utilized to achieve this amazing speed.
Asynchronous Requests:
In order for Sherlock to enumerate 323 websites in a fast an efficient method, asynchronous web request must be made. This allows python to send multiple web requests without having to wait for the previous request to finish.
Sherlock puts all 323 websites in a queue and then creates workers to send the requests and store the response for later use.
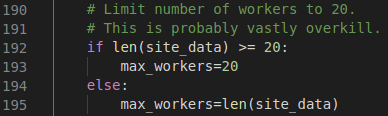
In the screenshot above, 20 workers at max are made. Unless the queue is less than 20, then the number of workers made equals the length of the queue. Without this workflow, Sherlock would be extremely slow.
Data.json:
The data.json file is the json database i referenced earlier and is the heart of Sherlock. Without this file, adding new websites to scan and testing the existing coverage would be difficult to assess.
Below is the first entry in data.json:
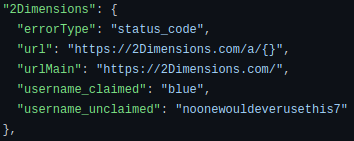
- the parent key name “2Dimensions” is the website name
- the value of the parent key consists of more key-value pairs
- the “errorType” key will tell Sherlock where to check if the username exists
- the “url” key is the website URL with username
- the “username_claimed” key is a valid username
- used for debugging purposes
- the “username_unclaimed” key is an invalid username
- used for debugging purposes
The first entry is a very basic example which is all that is needed for a simple website. But for more complex websites, additional key-value pairs are needed. Lets take a look at Snapchat’s json:
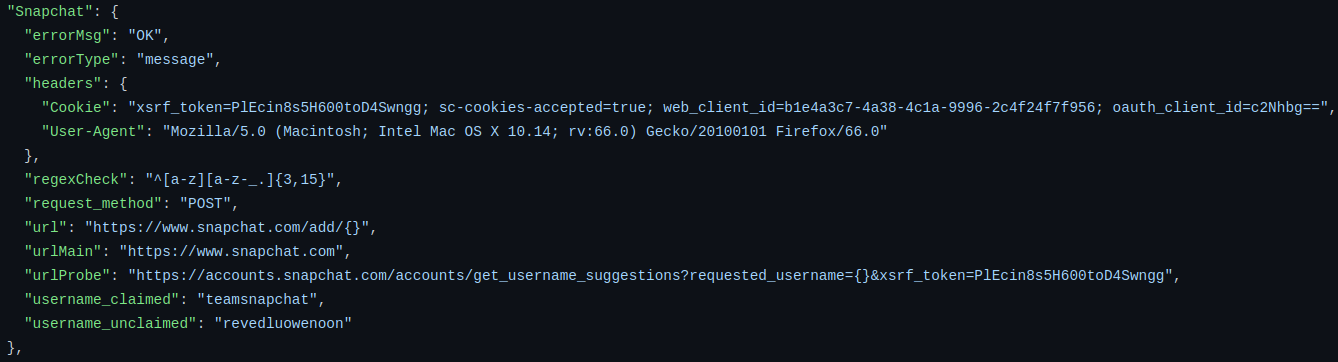
- the “errorMsg” key helps Sherlock determine if there is an issue with the request sent
- the “headers” key sets both a cookie and user-agent
- this is because snapchat actively filters out bots from connecting
- the “regexCheck” key evaluates the username to make sure it’s a valid format for the site
- this is because snapchat does not allow certain symbols in their usernames
- the “request_method” key tells Sherlock the type of web request to make
- the “urlProbe” key is a special URL for probing username existence
- sperate from where the user profile is normally found
As you can see, Snapchat requires more information to evaluate the existence of a username.
The data.json file streamlines adding new websites and predefines the web request that needs to be made.
Regex_check:
The “regex_check” key-value pair not only evaluates a valid username, but also helps speed up the execution time.
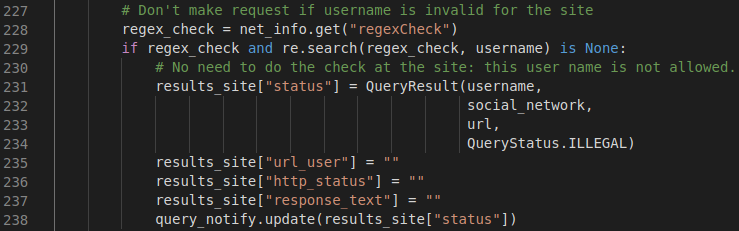
In the above screenshot, if the regex_check fails, then no web request is sent to the website and the next website in the queue is started. Cutting down on the number of web requests made will always speed up execution time.
Head Requests:
The head request will only return a website’s header information. In the data.json file, if “errorType” equals “status_code”, then only the returned response status code is needed to determine the existence of a username. Sherlock will always use a head request for a “status_code” check to decrease the size of data sent from the web server, which also decreases the time it takes to get a response from the web server.

This is a clever method to speed up the execution time.
Conclusion:
Sherlock is an excellent OSINT tool that makes username discovery shockingly easy. This tool makes me want to register a unique username every time I need a new account to prevent this tool being used against myself. Instead of Google Dorking, you should always run this tool first to gather information on a target account. What makes this tool most valuable is the fact that it still receives updates for new websites from the community. It will be interesting to see the how much the execution time increases once 500 or more websites are added.